[Android] Jsoup 라이브러리를 이용하여 웹 크롤링 (Web Crawling) 해보기 (AsyncTask, RxJava)
웹 크롤링
웹사이트(website), 하이퍼링크(hyperlink), 데이터(data), 정보 자원을 자동화된 방법으로 수집, 분류, 저장하는 것.
웹 크롤링은 이와 같이 인터넷에 나와있는 정보들을 수집하여 보여주는 기술이다.
안드로이드를 개발하면서 상당히 많이 사용되는 작업이기도 하다.
이 글에선 Jsoup 라이브러리를 이용하여 웹 크롤링을 할 것이다.
Jsoup 라이브러리
Jsoup 라이브러리에 대해 먼저 알아보자면, Java에서도 Jsoup 라이브러리를 사용해서 HTML 파싱을 할 수 있다.
파싱을 한글로 뜻풀이를 해보면 구문 분석이라는 뜻으로 문장을 이루고 있는 구성 성분을 분해하여 구조화하는 것을 의미한다.
따라서 HTML 태그 및 정보들을 가져와 새롭게 만들어 주는 것을 뜻한다.
Jsoup 라이브러리가 HTML 파싱을 지원하고 안드로이드 또한 Java 언어를 사용하기에 사용할 수 있다.
웹 크롤링 실습
웹 크롤링을 이용해서 게임 캐릭터 닉네임을 불러올 수 있는 예제를 만들어보기로 했다.
먼저 크롤링을 하기 위해 준비해야 할 기초 세팅을 할 것이다.
<Jsoup 라이브러리 추가>
프로젝트를 생성 후, 안드로이드 스튜디오에서 Jsoup 라이브러리를 사용하기 위해 모듈단위 build.gradle의 dependencies에 Jsoup라이브러리를 implementation 시켜준다.
라이브러리를 추가하는 코드를 작성하고 난 후, Sync Now를 눌러 라이브러리를 꼭 동기화시켜주자.
build.gradle (Module)
implementation 'org.jsoup:jsoup:1.13.1'버전은 글 작성 기준으로 1.13.1 버전을 사용했다.
<인터넷 권한 추가>
AndroidManifest.xml에서 인터넷 사용이 가능하도록 권한을 주고, HTTP 통신이 가능하게 하도록 하는 코드를 추가하여야 한다.
AndroidManifest.xml
<uses-permission android:name="android.permission.INTERNET"/>
//application 태그 안에 삽입
android:usesCleartextTraffic="true"
이렇게 하면 Jsoup을 사용하기 위한 기초 세팅이 끝이 났다.
다음은 크롤링을 할 정보를 정해야 한다.
어플리케이션을 만들 때 어떤 정보를 보여주고 싶은지 잘 생각해서 구상을 해야 한다.
<웹 페이지에서 태그 찾기>
작성자는 게임 캐릭터 닉네임을 불러오는 예제를 만들기로 했기 때문에 자주 즐겨하는 게임인 '로스트아크'의 전투정보실 사이트를 이용해서 닉네임을 불러올 생각이다.
우선 로스트아크 홈페이지에 보면 이렇게 캐릭터 정보를 표시해주는 사이트가 있다.

왼쪽 상단의 나와있는 닉네임을 가져올 생각이다.
이 화면에서 F12를 눌러 개발자 도구를 켜면 아래와 같은 창이 뜨는 것을 볼 수 있다.

닉네임 부분을 클릭하면 해당 위치의 태그를 확인할 수 있다.
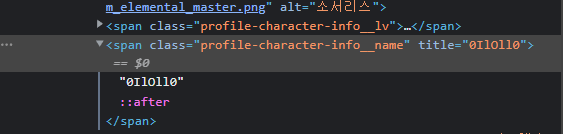
span 태그 안에 "profile-character-info__name"이라는 이름의 클래스가 있는 것을 볼 수 있다.
여기서 주의해야 할 점은 간혹 클래스 이름이 같거나 이름이 지정되어 있지 않은 클래스나 아이디들이 있는 경우도 있다.
이런 경우는 크롤링을 해도 값이 여러 개 혹은 없기 때문에 제대로 표시되지 않을 수 있다.
본격적으로 크롤링을 하기에 앞서, 가장 중요한 것을 알아야 한다.
안드로이드에서 Activity는 onCreate라는 메서드가 있고 이 메서드는 어플리케이션이 실행될 때 수행하는 코드들을 작성할 수 있다.
onCreate에 작성한 코드들은 하나의 스레드에서 실행이 되는데, 크롤링을 하기 위해 크롤링을 하는 코드를 넣으면 크롤링도 하나의 스레드에서 같이 실행이 되게 된다.
이렇게 되면 어플리케이션이 크롤링을 하는 시간에 정상적으로 어플리케이션 UI를 그릴 수 없게 된다.
따라서 크롤링은 새로운 스레드를 만들어 새로운 스레드에서 따로 실행해야 한다.
새로운 쓰레드에서 실행하는 비동기 구현 방법은 여러 가지가 있는데, Handler를 이용한 방법, AsyncTask를 이용한 방법, RxJava의 BackgroundTask를 이용한 방법, Kotlin의 Coroutine을 이용한 방법 등등 여러 가지가 있다.
Handler를 이용한 방법은 구글에 검색하면 가장 많이 노출되는 방법이므로 Handler를 이용한 방법은 배제하고, 이 글에선 AsyncTask를 이용한 방법과 RxJava의 BackgroundTask를 이용한 방법을 설명할 것이다.
(Coroutine을 이용한 방법은 아직 Kotlin을 배우는 중이기 때문에 나중에 따로 설명하는 시간을 가지도록 하겠다..)
<AsyncTask를 이용한 웹 페이지 크롤링>
activity_main.xml에 텍스트뷰를 하나 만들고 해당 텍스트뷰에 아이디를 출력하도록 할 것이다.
MainActiviy에 전역 변수로 텍스트 뷰 하나와 크롤링할 주소를 String 형태로 지정하여 URL을 보기 쉽게 만들어주었다.
MainActivity.java
TextView tv_textView;
String URLs = "https://lostark.game.onstove.com/Profile/Character/0iloll0";
비동기 작업을 위해 AsyncTask 함수를 만들어준다.
CharacterAsyncTask 클래스를 만들어 주었고 doInBackground, onPostExecute 오버라이드 함수를 만들면 된다.
- doInBackground(): 백그라운드(새로 만들어진 스레드)에서 작업할 내용을 담는 함수
- onPostExecute(): 백그라운드 작업이 끝나면 호출이 되고 메모리 리소스를 해체하는 함수
이외에도 여러 메소드들이 있지만 자세하게 다루지 않을 것이다.
자세한 내용은 AsyncTask를 검색해보자.
우리는 doInBackground() 안에 크롤링하는 코드를 작성하면 된다.
class CharacterAsyncTask extends AsyncTask<String, Void, String> {
TextView textView;
public WeatherAsyncTask(TextView textView) {
this.textView = textView;
}
@Override
protected String doInBackground(String... strings) {
return null;
}
@Override
protected void onPostExecute(String s) {
super.onPostExecute(s);
textView.setText(s); //onPostExecute에서 textView에 결과를 넣는것도 잊지 말자.
}
}
doInBackground() 안에 다음과 같이 크롤링하는 주요 코드를 작성하면 된다.
먼저 Jsoup의 connect() 함수를 사용하여 URL을 연결시켜주고 .get() 함수를 통해 해당 URL의 HTML 코드를 모두 가져와 document에 저장한다.
그중 class이름이 profile-character-info__name인 span 태그를 elements에 저장한다.
클래스 내부에 elements가 하나인 이 예제에는 적용되지 않지만, 태그 안 elements가 여러 개일 경우 for문을 통해 모든 elements를 result에 저장해주면 된다.
크롤링하는 부분은 try-catch 구문 안에 넣어 예외처리를 꼭 하도록 하자.
String result = "";
try {
Document document = Jsoup.connect(URLs).get();
Elements elements = document.select("span[class=profile-character-info__name]");
for (Element element : elements) {
result = result + element.text() + "\n";
}
return result;
} catch (IOException e) {
e.printStackTrace();
}
onCreate에서 AsyncTask 함수를 불러와 excute()로 호출을 하면 된다.
@Override
protected void onCreate(Bundle savedInstanceState) {
super.onCreate(savedInstanceState);
setContentView(R.layout.activity_main);
tv_textView = findViewById(R.id.tv_textView);
new CharacterAsyncTask(tv_textView).execute();
}
AsyncTask는 2019년 11월 8일부로 Android 11에서 Deprecated 되었다.
따라서 BackgroundTask나 Coroutine으로 넘어가는 추세이고 AsyncTask 말고도 Handler 같은 비동기 처리 방식들이 여러 가지 있기 때문에 AsyncTask 방식을 추천하진 않지만 공부 차원에서 남겨놓았다.
<BackgroundTask를 이용한 웹 페이지 크롤링>
BuildGradle에 RxJava를 사용하기 위해 라이브러리를 추가해준다.
build.gradle (Module)
implementation 'io.reactivex.rxjava3:rxandroid:3.0.0'
implementation 'io.reactivex.rxjava3:rxjava:3.0.7'
activity_main.xml에 텍스트뷰를 하나 만들고 해당 텍스트뷰에 아이디를 출력하도록 할 것이다.
MainActiviy에 전역 변수로 텍스트 뷰 하나와 크롤링할 주소를 String 형태로 지정하여 URL을 보기 쉽게 만들어주었다.
MainActivity.java
TextView tv_textView;
String URLs = "https://lostark.game.onstove.com/Profile/Character/0iloll0";
비동기 작업을 위해 MainActivity 클래수 내부에 BackgroundTask 메서드를 만들어준다.
BackgroundTask 내부에 onPreExecute, doInBackground, onPostExecute 주석 달린 부분이 해당 코드를 수행하는 부분이다.
- onPreExecute: Task 시작 전 실행될 내용을 담는 부분
- doInBackground: Task(새로 만들어진 스레드)에서 실행될 내용을 담는 부분
- onPostExecute: Task 끝난 후 실행될 내용을 담는 부분
RxJava의 BackgroundTask에 관한 자세한 설명은 검색해보자.
우리는 doInBackground 안에 크롤링하는 코드를 작성하면 된다.
Disposable backgroundTask;
void BackgroundTask(String URLs) {
//onPreExecute
backgroundTask = Observable.fromCallable(() -> {
//doInBackground
return null;
}).subscribeOn(Schedulers.io())
.observeOn(AndroidSchedulers.mainThread())
.subscribe((result) -> {
//onPostExecute
backgroundTask.dispose();
});
}
doInBackground 안에 다음과 같이 크롤링하는 주요 코드를 작성하면 된다.
먼저 Jsoup의 connect() 함수를 사용하여 URL을 연결시켜주고 .get() 함수를 통해 해당 URL의 HTML 코드를 모두 가져와 document에 저장한다.
그중 class이름이 profile-character-info__name인 span 태그를 elements에 저장한다.
클래스 내부에 elements가 하나인 이 예제에는 적용되지 않지만, 태그 안 elements가 여러 개일 경우 for문을 통해 모든 elements를 result에 저장해주면 된다.
크롤링하는 부분은 try-catch 구문 안에 넣어 예외처리를 꼭 하도록 하자.
String result = "";
try {
Document document = Jsoup.connect(URLs).get();
Elements elements = document.select("span[class=profile-character-info__name]");
for (Element element : elements) {
result = result + element.text() + "\n";
}
return result;
} catch (IOException e) {
e.printStackTrace();
}
onPostExecute에서 textView에 결과를 넣는 것도 잊지 말자.
//onPostExecute
tv_textView.setText(result);
onCreate에서 BackgroundTask 메소드를 불러와 호출을 하면 된다.
@Override
protected void onCreate(Bundle savedInstanceState) {
super.onCreate(savedInstanceState);
setContentView(R.layout.activity_main);
tv_textView = findViewById(R.id.tv_textView);
BackgroundTask(URLs);
}
웹 크롤링 실습 결과
다음과 같이 어플리케이션을 실행해보면 닉네임이 잘 뜨는 것을 볼 수 있다.

예제의 전체 소스코드는 깃허브 링크를 첨부해놓았다.
https://github.com/Sangyoon98/Crawling_Example.git
GitHub - Sangyoon98/Crawling_Example
Contribute to Sangyoon98/Crawling_Example development by creating an account on GitHub.
github.com